✅ 오늘 한 것
데이터 전처리 & 시각화 강의 수강
✏️ 오늘 배운 점
데이터 전처리 & 시각화
데이터 분석가란?
비즈니스 분석가 : 비즈니스 문제를 이해하고 해결하기 위해 데이터 분석
프로덕트 분석가 : 제품이나 서비스의 성과를 평가하고 개선하기 위해 데이터 분석
BI 분석가 : 기업의 비즈니스 인텔리전스 플랫폼과 도구를 사용하여 데이터를 시각화하고 보고서 작성
데이터 분석가 : 정형 데이터를 분석하여 기업의 의사 결정 지원
데이터 사이언티스트 : 데이터를 활용하여 예측, 패턴 발견, 복잡한 분석을 수행하여 문제 해결
데이터 전처리와 시각화는 왜 해야 하는가?
상대방을 설득하기 위하여 데이터를 잘 전달해야 할 필요성이 있는 것이고, 잘 전달하는 방법 중 하나가 시각화다. 또한, 데이터를 잘 시각화하기 위해서 목적에 맞게 데이터 전처리가 중요하다.
하지만, 데이터 전처리와 시각화를 하기 전에 어떠한 목적으로 데이터를 분석할 것인가?를 생각해야 한다.
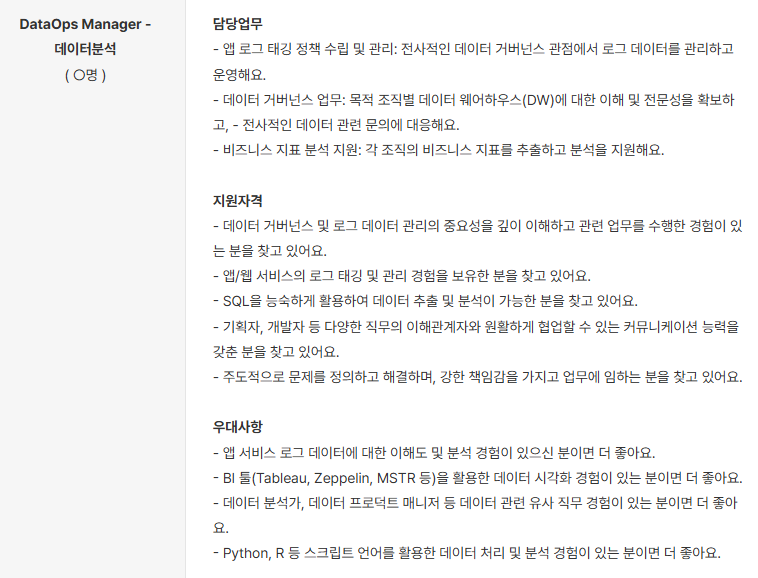
채용공고 스크랩하기




Chapter 2
데이터 전처리: 내가 원하는 데이터를 보기 위해 하는 모든 활동
DataFrame = 표 형태
- index : 각 아이템을 특정할 수 있는 고유의 값
- columns : 하나의 속성을 가진 데이터 집합
Series = 하나의 속성을 가진 데이터 집합
- value + index
Chapter 3
컬럼(Column) : 데이터프레임의 열(또는 변수)
.head(N) : 데이터를 순서대로 N개 행까지 보여준다.
.info() : 데이터의 정보 파악(인덱스, 컬럼명, 컬럼의 데이터 개수, 데이터 타입)
.describe() : 데이터의 기초통계량 확인(개수, 평균, 표준편차, 사분위, 중앙값)
isnull() : 결측치 확인
dropna() : 결측치 제거
duplicated() : 중복 데이터 확인
drop_duplicated() : 중복 데이터 제거
iloc : 정수(int) 기반의 인덱스 사용
.iloc[row, column] : 인덱스 번호로 선택
loc : 레이블 기반의 인덱스 사용
loc[row, column] : 이름으로 선택
불리언 인덱싱(Boolean Indexing) : 조건을 이용하여 데이터프레임에서 특정 조건을 만족하는 행을 선택하는 방법
데이터를 필터링하거나 원하는 조건을 만족하는 행 추출
isin() : 데이터프레임의 값들 중에서 특정 값이나 리스트 안에 포함된 값을 찾아내는 메소드
concat() : 데이터프레임을 위아래, 좌우로 연결
axis : 연결하고자 하는 축(방향) 지정(기본값 = 0(위아래 연결), =1(좌우로 연결))
ignore_index : 기본값 False(연결된 결과 데이터프레임의 인덱스 유지), True(기존 인덱스를 무시하고 새롭게 인덱스 설정)
merge()
- how : 병합 방법을 나타내는 매개변수
'inner' : 공통된 키(열)를 기준으로 교집합 생성
'outer' : 공통된 키를 기준으로 합집합 생성
'left' : 왼쪽 데이터프레임의 모든 행을 포함하고 오른쪽 데이터프레임은 공통된 키에 해당하는 행만 포함
'right' : 오른쪽 데이터프레임의 모든 행을 포함하고 왼쪽 데이터프레임은 공통된 키에 해당하는 행만 포함
on : 병합 기준이 되는 열 이름을 지정
left_on과 right_on : 왼쪽 데이터프레임과 오른쪽 데이터프레임에서 병합할 열 이름이 다른 경우에 사용
groupby() : 데이터프레임을 그룹화하고, 그룹 단위로 데이터를 분할(split), 적용(apply), 결합(combine)하는 기능 제공
pivot_table() : 데이터프레임에서 피벗 테이블을 생성하는 데 사용
sort_index : index를 순서에 맞게 정렬
set_index() : ()안에 위치한 객체를 index로 지정
sort_values() : 컬럼 기준으로 정렬
sort_index() : 인덱스 기준으로 정렬
chapter 4
Matplotlib : 파이썬에서 시각화를 위한 라이브러리 중 하나로, 다양한 종류의 그래프를 생성하기 위한 도구 제공
• 그래프를 색상, 스타일, 레이블, 축 범위 등을 조절하여 원하는 형태로 시각화 가능
• 선 그래프, 막대 그래프, 히스토그램, 산점도, 파이 차트 등 다양한 시각화 방식 지원
plot() : dataframe 객체에서 데이터를 시각화하는데 사용(ex. plot(x, y))
- plot()에서 사용가능한 스타일 지정
color : 문자열로 지정(기본 색상 이름 or RGB 값으로 지정)
linestyle : '-'(실선), '--'(대시선), ':'(점선), '-.'(점-대시선) 등으로 지정
marker : 데이터 포인트를 나타내는 기호(다양한 기호로 지정 가능)
label : 각 시각화된 그래프 형식이 어떤 데이터 값인지 나타낼 수 있도록 하는 도구
legend() : 그래프의 범례 추가
set_xlabel() : x축 레이블 제목 추가
set_ylabel() : y축 레이블 제목 추가
set_title() : 그래프 제목 추가
text() : 특정 위치에 텍스트 추가
plt.figure() : 그래프를 원하는 크기로 설정 가능(가로, 세로 크기를 인치 단위로 설정)
| 그래프 유형 | 자료 유형 | 특징 |
| Line Plot | 연속형 데이터 | 데이터의 변화 및 추이를 시각화 |
| Bar Plot | 범주형 데이터 | 카테고리 별 값의 크기를 시각적으로 비교 |
| Histogram | 연속형 데이터 | 데이터 분포, 빈도, 패턴 등을 이해 |
| Pie Chart | 범주형 데이터의 비율 | 범주별 상대적 비율을 부채꼴 모양으로 시각화 |
| Box Plot | 연속형 데이터의 분포 | 중앙값, 사분위수, 최소값, 최대값, 이상치 확인 |
| Scatter Plot(산점도) | 두 변수 간 관계 | 변수 간의 관계, 군집, 이상치 등 확인 |
Line Plot : plt.plot(x, y)
Bar Plot : plt.bar(x, y)
Histogram : plt.hist(data, bins = )
Pie Chart : plt.pie(sizes, labels=labels, autopct='%1.1f%%')(원 그래프이기에 xlabel과 ylabel이 없다.)
Bot Plot : plt.boxplot
Scatter Plot : plt.scatter (주로 피어슨 상관계수 사용 : .corr(method='Pearson')
데이터 전처리 & 시각화를 하기 전 상기할 리스트
1. 목표설정하기 : 무엇을 위해 데이터 전처리와 시각화가 필요한 것인가?
2. 예상 산출물 정의하기 : 데이터 처리 및 시각화해서 나타날 예상 결과물은 무엇인가?
3. 'As-is' vs 'To-be' 생각하기 : 현재 문제와 상황이 무엇인지 인지하고 어떤식으로 개선할 것인가 방향성 설정
- 대표적인 Pandas 라이브러리
Matplotlib, Seaborn, Plotly
- 데이터 시각화 툴
Tableau, Google Data Studio, Amazon QuickSight
✏️ 오늘의 핵심
데이터 전처리 & 시각화 강의를 들으면서 라이브러리와 관련된 내용 중 새롭게 보거나 중요하다고 생각되는 내용들을 정리하였다.
데이터 전처리와 시각화는 단순히 기술적인 과정이 아니라, 분석 목적을 명확히 정의하고 그 목적에 맞게 데이터를 가공·표현하는 과정임을 배웠다.
데이터프레임 다루기, 결측치·중복 처리, 그룹화와 피벗 테이블 같은 전처리 기법을 통해 원하는 데이터를 만들고, Matplotlib과 같은 라이브러리를 활용해 목적에 맞는 그래프를 선택해 시각화해야 한다.
📌추가로 해야할 점
코드카타(Python)
'품질관리(QAQC) 데이터 부트캠프(본캠프)' 카테고리의 다른 글
| 본캠프_3주차(5일)_TIL (0) | 2025.09.25 |
|---|---|
| 본캠프_3주차(4일)_TIL (0) | 2025.09.25 |
| 본캠프_3주차(2일)_TIL (0) | 2025.09.23 |
| 본캠프_3주차(1일)_TIL (0) | 2025.09.22 |
| 본캠프_2주차(5일)_TIL (0) | 2025.09.19 |