✅ 오늘 한 것
최종 프로젝트
✏️ 오늘 배운 점
1. 하이퍼 파라미터 튜닝이란?
머신러닝 모델이 학습을 시작하기 전에 사용자가 직접 설정해야 하는 설정값(Hyperparameter)을 최적화하는 과정. 모델의 성능(정확도 등)을 극대화하기 위해 필수적인 단계이다.
2. GridSearchCV
Scikit-learn에서 제공하는 가장 대표적인 튜닝 방법. 사용자가 지정한 파라미터의 모든 조합(Grid)을 시도하여 최적의 값을 찾는다.
주요 특징
- 교차 검증(Cross Validation) 지원: 단순히 데이터를 한 번 나누는 것이 아니라, 여러 번 나누어 검증하므로 신뢰도가 높다.
- 전수 조사: 지정된 범위 내의 모든 경우의 수를 확인하므로, 범위 내 최적해를 보장한다. (단, 시간이 오래 걸릴 수 있음)
3. 구현 코드 (예시: Random Forest)
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV, train_test_split
from sklearn.metrics import accuracy_score
# 1. 데이터 준비
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(
iris.data, iris.target, test_size=0.2, random_state=42
)
# 2. 모델 및 파라미터 그리드 설정
rf_model = RandomForestClassifier(random_state=42)
param_grid = {
'n_estimators': [50, 100, 200], # 트리의 개수
'max_depth': [None, 6, 10], # 트리의 깊이
'min_samples_leaf': [1, 2, 4] # 리프 노드 최소 샘플 수
}
# 3. GridSearchCV 객체 생성 및 학습
grid_cv = GridSearchCV(
estimator=rf_model,
param_grid=param_grid,
cv=5, # 5-Fold 교차 검증
n_jobs=-1, # 모든 CPU 코어 사용 (속도 향상)
refit=True # 최적 파라미터로 모델 재학습
)
grid_cv.fit(X_train, y_train)
# 4. 결과 확인
print(f"최적 파라미터: {grid_cv.best_params_}")
print(f"최고 정확도(CV): {grid_cv.best_score_:.4f}")
# 5. 평가 (refit=True 덕분에 바로 predict 가능)
best_model = grid_cv.best_estimator_
acc = accuracy_score(y_test, best_model.predict(X_test))
print(f"테스트 정확도: {acc:.4f}")
4. 핵심 옵션 정리
- cv: 교차 검증 횟수. 보통 5 또는 10을 사용. 과적합(Overfitting)을 방지하는 데 중요하다.
- n_jobs=-1: 병렬 처리를 허용하여 컴퓨터의 모든 코어를 사용한다. 탐색 속도를 높이는 꿀팁.
- refit=True: 최적의 파라미터를 찾은 뒤, 전체 학습 데이터셋으로 해당 모델을 다시 학습시킨다. 별도로 fit()을 다시 호출할 필요가 없어 편리하다.
5. 추가로 알게 된 점 (Advanced)
- RandomizedSearchCV: 파라미터 조합이 너무 많아 시간이 오래 걸릴 때 사용한다. 모든 조합을 다 보는 대신, 랜덤하게 몇 개만 뽑아서 테스트한다. 대용량 데이터에서 유리하다.
- Optuna: 베이지안 최적화 기반의 라이브러리로, GridSearch보다 더 스마트하고 효율적으로 최적값을 찾아준다. (추후 학습 예정)
머신러닝 구동을 완료하고 대시보드를 구상하는 과정에서 모델 학습에 문제가 발생하였다.
코드의 성능 지표를 높이기 위해서 앙상블을 진행하는 방식으로 진행을 하였지만 대시보드를 구상하는 데에 있어서는 또 다른 문제가 발생할 수 있을 수 있다는 점을 인지하지 못하면서 생긴 오류다.
그렇기에 단일 모델로 다시 데이터 분석 과정을 거치면서 배운 정보를 기반으로 성능 지표(MCC)를 우선 순위로 두고 모델을 다시 비교하여 High Recall & Preicison을 위한 각 모델을 다시 선정하는 순서로 넘어갔다.
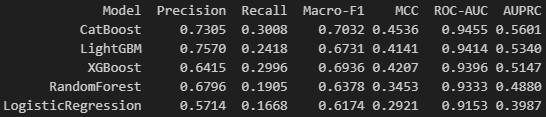

이전에는 2-stage filtering에서 stage 1에서는 CatBoost + LGBM을 사용하여 High Recall을 이끌어내기 위해 진행하였고, stage 2에서는 MLP + XGBoost을 사용하여 High Precision을 이끌어내기 위하여 진행을 했었기에 어느 정도의 베이스는 존재했다.
따라서, stage 1에서는 CatBoost를 단일 모델로서 활용하여 High Recall을 이끌어낼 수 있다고 판단했고, stage 2에서는 SVM 또는 XGBoost를 사용하면 High Precision을 이끌어낼 수 있다고 판단했다. 성능 지표 또한 튜닝을 통하여 가져올 수 있다고 판단했다.
📌추가로 해야 할 점
최종 프로젝트
'품질관리(QAQC) 데이터 부트캠프(본캠프)' 카테고리의 다른 글
| 본캠프_19주차(금)_TIL(최종 프로젝트) (0) | 2026.01.23 |
|---|---|
| 최종 프로젝트 중간 점검 (0) | 2026.01.22 |
| 본캠프_19주차(수)_TIL(최종 프로젝트: 중간 발표회 & 피드백) (0) | 2026.01.21 |
| 본캠프_19주차(화)_TIL(최종 프로젝트) (0) | 2026.01.20 |
| 본캠프_19주차(월)_TIL(최종 프로젝트) (0) | 2026.01.19 |