데이터 불균형과 싸우며 최적의 모델을 찾기까지
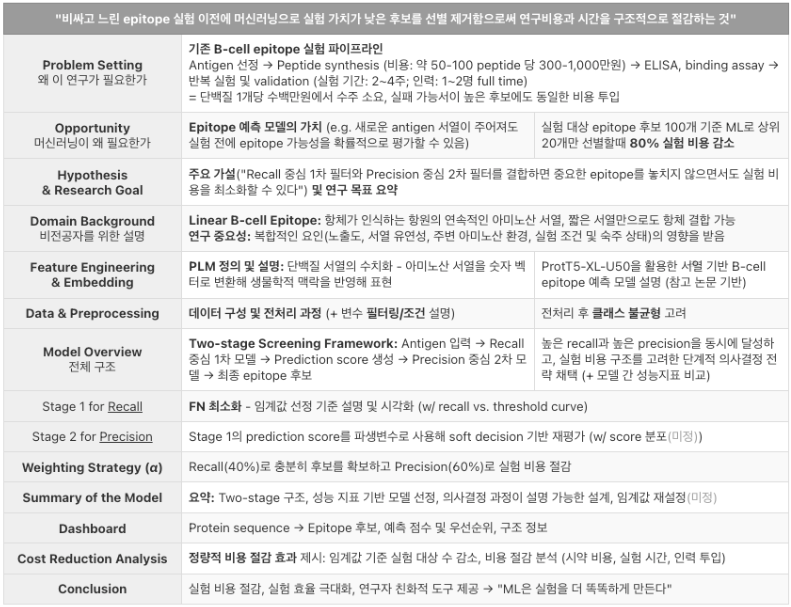
1. 프로젝트 개요 & 목표
주제: 항원(Antigen) 데이터를 활용한 질병/상태 분류 예측 모델 개발
핵심 목표:
- 단순 정확도가 아닌 실질적인 예측력을 나타내는 MCC가 0.3 이상 달성하는 모델 선정
- 모델의 목적에 따라 High Recall 또는 High Precision을 선택적으로 최적화
2. 주요 난관 및 애로사항 (The Struggle)
🚨 1. "99%의 함정": 극심한 데이터 불균형 (Class Imbalance)
- 문제 상황: Negative 데이터가 압도적으로 많아, 모델이 무조건 "Negative"로만 예측해도 정확도가 90% 이상 나오는 현상 발생. 정작 중요한 Positive(질병/상태)는 전혀 맞추지 못함.
- 힘들었던 점:
- 단순히 데이터를 늘릴 수가 없었음.
- 모델이 학습을 '포기'하고 쉬운 길(All Negative)만 택하려 함.
- 해결책:
- Class Weight 조절: scale_pos_weight를 단순 비율(ratio)뿐만 아니라, multiplier(1.5배~5배)를 적용하여 모델에게 "틀리면 크게 혼난다"는 신호를 줌.
- 평가 지표 변경: Accuracy를 버리고 MCC(Matthews Correlation Coefficient)와 Recall/Precision을 메인 지표로 선정.
🤯 2. "최적의 파라미터를 찾아서": 튜닝의 딜레마
- 문제 상황: 모델(CatBoost, XGBoost)의 파라미터가 너무 많음.
- 시행착오:
- 초반에 GridSearchCV를 시도했으나, 모든 조합을 다 돌리느라 시간이 너무 오래 걸리고 비효율적이었음.
- 단순히 파라미터만 돌리니 과적합(Overfitting)이 발생하거나, 학습 시간이 무한정 길어짐.
- 해결책:
- Optuna 도입: 베이지안 최적화 방식을 사용하여 스마트하게 탐색 범위를 좁힘.
- Custom Objective: 단순히 점수만 높이는 게 아니라, if mcc >= 0.3 return recall과 같이 조건부 최적화 로직을 구현하여 "최소한의 건전성"을 확보함.
🛠 3. Feature Engineering의 오해와 진실
- 문제 상황: 습관적으로 모든 범주형 변수에 One-Hot Encoding(OHE)을 적용함.
- 깨달음:
- 차원이 너무 늘어나 학습 속도가 저하됨.
- CatBoost는 자체적으로 범주형 변수를 처리하는 알고리즘(cat_features)이 훨씬 강력하다는 것을 알게 됨.
- 해결책:
- OHE 코드를 제거하고, 데이터를 String 타입으로 변환하여 모델에 직접 주입.
- 결과적으로 코드도 간결해지고 학습 성능도 향상됨.
📉 4. "운빨"을 제거하라: 검증 신뢰성 문제
- 문제 상황: train_test_split으로 한 번만 나눈 데이터(Hold-out)로 튜닝했을 때, 검증 세트에 따라 점수가 들쭉날쭉함. 내가 찾은 파라미터가 진짜 좋은 건지, 운이 좋았던 건지 확신할 수 없었음.
- 해결책:
- Stratified K-Fold (5-Fold) + Early Stopping 도입.
- 시간은 더 걸리지만, 5번의 테스트를 거쳐 평균적으로 잘하는 파라미터를 찾아내어 "모델의 일반화 성능"을 확보함.
3. 최종 기술 스택 및 전략 (Solution)
- 모델: CatBoost Classifier (High Recall 전략), XGBoost (High Precision 전략)
- 최적화 도구: Optuna (Multi-objective optimization logic 적용)
- 검증 전략: Stratified K-Fold CV
- 핵심 파라미터:
- scale_pos_weight: 불균형 해소의 핵심 Key.
- cat_features: CatBoost 성능 극대화.
- early_stopping_rounds: 학습 효율성 증대.
4. 회고 및 배운 점 (Retrospective)
- "튜닝은 무작정 돌리는 게 아니라 전략이다."
- 무조건 GridSearch를 돌리는 것보다, 모델이 어떤 파라미터에 민감한지 파악하고 Optuna로 효율적으로 찾는 것이 중요하다는 것을 배움.
- "평가 지표가 모델의 운명을 결정한다."
- 비즈니스 목표(놓치면 안 되는가? 오진하면 안 되는가?)에 따라 Recall과 Precision 중 무엇을 택할지, 그리고 MCC로 어떻게 밸런스를 잡을지 고민하는 과정이 가장 의미 있었음.
- "데이터 전처리는 모델에 맞게."
- 남들이 다 한다고 OHE를 하는 게 아니라, 사용하는 모델(CatBoost)의 특성에 맞춰 전처리 방식을 바꿔야 한다는 점을 배움.
이후 PPT에서 표현해야 할 요소
'품질관리(QAQC) 데이터 부트캠프(본캠프)' 카테고리의 다른 글
| 본캠프_20주차(월)_TIL(머신러닝 모델 최적화 & 코드 정리) (0) | 2026.01.26 |
|---|---|
| 본캠프_19주차(금)_TIL(최종 프로젝트) (0) | 2026.01.23 |
| 본캠프_19주차(목)_TIL(최종 프로젝트) (0) | 2026.01.22 |
| 본캠프_19주차(수)_TIL(최종 프로젝트: 중간 발표회 & 피드백) (0) | 2026.01.21 |
| 본캠프_19주차(화)_TIL(최종 프로젝트) (0) | 2026.01.20 |