✅ 오늘 한 것
최종 프로젝트
✏️ 오늘 배운 점
머신러닝 모델을 돌릴 때 cpu로만 돌리면 한계점이 많다는 것을 확인할 수 있었다.
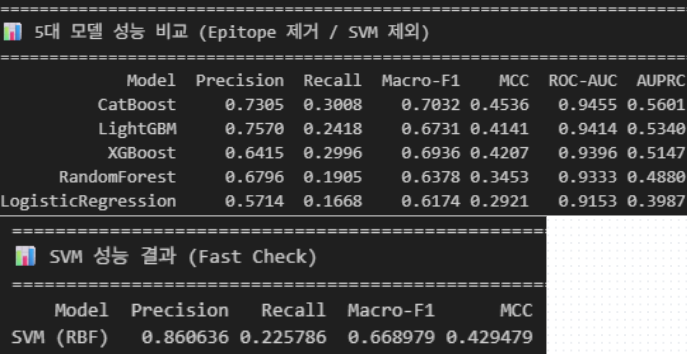
상대적으로 Precision & MCC가 높은 것들을 우선적으로 선별하여 CatBoost, LightGBM, SVM을 1차 선별할 수 있었다.
이후, CatBoost는 이전에도 1차 선별(High Recall)에 사용했던 앙상블 모델의 일부였기에 그대로 1차 선별에 활용하고 2차 선별은 Precision이 높았던 LightGBM과 SVM 중 하나를 택해야했다.
하지만, SVM이 이 프로젝트에서 큰 도움이 된 레퍼런스(논문)에서 좋은 성능을 보였다는 것을 알고 있었기에 SVM을 진행하기 위해서 모델 학습을 돌렸으나 데이터 양이 많아서 돌리지를 못하면서 LightGBM로 2차 선별 모델을 선정하게 되었다.

단일 서열 분석 및 3D Mapping 자동화 (app.py)
- Sequence Index Mapping: 전체 안티젠 서열 입력 시, DB 내의 16mer 조각 서열과 대조하여 해당 조각이 전체 서열의 몇 번째 인덱스(Start~End)에 위치하는지 계산하는 기능을 구현함.
- AlphaFold DB API 연동: 사용자가 PDB ID를 직접 입력하지 않아도, 입력된 아미노산 서열을 기반으로 UniProt API를 호출하여 고유 ID를 찾고, AlphaFold DB에서 최적의 3D 구조(.pdb)를 실시간으로 다운로드하는 파이프라인을 구축함.
- 3Dmol.js 시각화 최적화:
- 3D 구조 내에서 에피토프로 예측된 특정 잔기(Residue) 영역만 빨간색(Red)으로 하이라이트 처리함.
- 사용자 경험을 위해 분석 완료 시 해당 에피토프 영역으로 카메라가 자동 클로즈업(zoomTo)되도록 설정함.
2. Streamlit Multi-Page 아키텍처 도입
- 구조적 분리: 단일 분석(app.py)과 대량 분석(pages/) 페이지를 분리하여 서비스의 확장성을 확보함.
- 경로 관리(Path Management): 하위 폴더(pages/) 내의 스크립트가 상위 폴더의 models 및 data 리소스를 정확히 참조할 수 있도록 os.path 기반의 절대 경로 로직을 정교화함.
3. 대량 서열 스크리닝 기능 구현 (pages/2_Batch_Screening.py)
- Dynamic Column Selection: 사용자가 CSV 파일을 업로드하면 서열 데이터가 포함된 컬럼을 직접 선택할 수 있도록 st.selectbox를 활용한 유연한 UI를 설계함.
- Vectorized DB Matching: 업로드된 파일의 수많은 서열을 기존 test_metadata.csv 및 test_embedding_antigen.npy와 대조하여, 별도의 임베딩 생성 과정 없이 기존 임베딩 수치를 즉시 매핑하는 효율적인 검색 시스템을 구축함.
- Batch Filtering & Export: Stage 1 모델(CatBoost)을 통해 Score 0.2 이상인 유효 후보군만 선별하고, 원본 데이터의 정보를 유지한 채 결과를 다시 CSV 파일로 다운로드할 수 있는 기능을 완성함.
4. 주요 기술적 해결(Troubleshooting)
- JS Escape Error: PDB 데이터 로드 시 자바스크립트 백틱(`)이나 줄바꿈 문자로 인해 발생하는 렌더링 오류를 문자열 이스케이프(replace) 처리를 통해 해결함.
- Deep Search Logic: API 호출 시 발생하는 타임아웃 및 검색 실패 문제를 해결하기 위해 검색 대기 시간 연장 및 재시도 로직을 도입하여 구조 탐색의 안정성을 높임.
✏️ 오늘의 질문
1. 모델 용량 제한에 의해 대시보드에 모델 구현이 불가능한데 어떠한 방법으로 진행할 수 있나요?
- Streamlit: ui 구성 + fast api: 모델 따로 불러오기
- git lfs
| 비교 항목 | Git LFS (일체형) | FastAPI + Streamlit (분리형) |
| 구조 | Streamlit 서버가 모델 로드/계산까지 수행 | Streamlit은 화면만 보여주고, 계산은 API 서버가 수행 |
| 난이도 |
매우 쉬움 (기존 코드 유지)
|
어려움 (서버 간 통신/배포 설정 필요)
|
| 속도 | 로컬 연산이라 통신 지연 없음 (단, 서버 사양에 의존) | 네트워크 통신(JSON) 지연 발생 |
| 확장성 | 낮음 (모델이 많아지면 서버가 못 버팀) |
매우 높음 (모델 서버만 여러 대로 증설 가능)
|
| 비용 | 단일 서버 비용만 발생 | 최소 2개의 서버 운영 비용 발생 |
📌추가로 해야 할 점
최종 프로젝트
'품질관리(QAQC) 데이터 부트캠프(본캠프)' 카테고리의 다른 글
| 본캠프_20주차(화)_TIL(대시보드 구현) (0) | 2026.01.27 |
|---|---|
| 본캠프_20주차(월)_TIL(머신러닝 모델 최적화 & 코드 정리) (0) | 2026.01.26 |
| 최종 프로젝트 중간 점검 (0) | 2026.01.22 |
| 본캠프_19주차(목)_TIL(최종 프로젝트) (0) | 2026.01.22 |
| 본캠프_19주차(수)_TIL(최종 프로젝트: 중간 발표회 & 피드백) (0) | 2026.01.21 |