✅ 오늘 한 것
머신러닝 기초
✏️ 오늘 배운 점
실무에 바로 쓰는 머신러닝 기초
1-1 머신러닝이란?
1. 머신러닝이란?
- 머신러닝 3대 요소
1. 데이터: 데이터가 참고하는 정보의 모음
2. 알고리즘(모델): 문제를 해결하기 위해 순서대로 처리하는 방법이나 규칙
3. 컴퓨팅 파워: 컴퓨터가 얼마나 빠르고 많이 일(연산)을 할 수 있는지를 나타내는 능력치
인공지능(AI): 사람의 지능적인 작업을 기계가 수행하도록 만드는 광범위한 개념
머신러닝: AI를 실현하기 위한 방법 중 하나로, 데이터로부터 특징이나 규칙을 찾아내서 학습하는 것
딥러닝: 머신러닝의 하위 분야로, 사람의 뇌신경을 본 떠 만든 인공신경망으로 이루어져 있음.
인공신경망을 여러 겹 쌓아서 복잡한 정보를 학습할 수 있음.
2. 머신러닝의 역할 및 중요성
빅데이터: 일반적인 방법으로는 저장∙분석하기 힘들 만큼 방대한 양의 데이터
기존 방식으로는 처리하기 어려웠던 빅데이터 활용 가능
3. 머신러닝 vs 기존 통계 분석
가설 검증 vs 예측 성능
- 통계 분석
- 가설 검증, 추론
- 주로 "왜?"라는 질문에 집중
- 표본 수가 커지면 더 정교한 추론이 가능하지만, 일반적으로 가설 자체는 사람이 세움.(통계는 질문에 대한 답변만 진행할 수 있기에 질문을 던지는 것은 사람이기에 도구의 한계를 설명)
- 머신러닝
- 예측(얼마나 정확하게 미래나 미지의 데이터를 예측할 수 있는가)
- "얼마나 잘?"에 집중(정확도, 재현율 등)
- 데이터가 많을수록 학습에 유리하며, 더 좋은 모델을 만들 수 있음.
4. 머신러닝의 종류
지도학습: 정답(Label)이 있는 데이터를 학습하는 방식
- 분류(Classification): 어느 그룹에 속하는지를 결정(정해진 카테고리 중 하나 선택)
- 회귀(Regression): 숫자로 된 결과를 예측(연속적인 값)
비지도학습: 정답(Label)이 없는 데이터 패턴을 스스로 찾는 방식
- 군집화(Clustering): 성향이 비슷한 사람이나 사물을 자동으로 묶어내는 기법
- 차원 축소(Dimensionality Reduction): 데이터의 특징(변수)이 너무 많아서 복잡한 데이터를 핵심 정보만 남기고 압축하는 기법
강화학습: 에이전트가 환경과 상호작용하며 보상을 최대화하도록 학습
시뮬레이션 환경에서 시도-오류를 반복하며 가장 높은 보상을 보장해주는 행동 규칙(전략)을 학습
5. 머신러닝 모델링 과정
데이터 수집
- 웹 크롤링, 센서 측정, 설문조사, DB 추출 등 다양한 방법
- 양질의 데이터 확보가 프로젝트 성패를 좌우
전처리
- 결측치 처리
- 결측치: 데이터 표에서 일부 셀이 비어 있는 상태
- 빈 칸을 Mean이나 Mode로 대체하거나 제거한 이후 분석
- 이상치 처리
- 데이터의 범위에서 심하게 벗어난 값 해결
- 스케일링
- 각각 다른 단위를 쓰는 데이터를 비슷한 수준으로 맞춰주는 작업
- 범주형 변환
- 글자로 된 정보를 숫자로 바꿔주는 작업
- One-Hot Encoding -> 해당 범주에 속하면 1, 아니면 0을 넣는 방식
- Label Encoding -> 순서대로 숫자 부여(숫자에 순위 의미가 생겨버릴 수 있기에 주의 필요)
모델링
- 지도학습: 분류/회귀 알고리즘 선택(ex: 로지스틱 회귀, 랜덤 포레스트, XGBoost 등)
- 비지도학습: 클러스터링/차원 축소 알고리즘 선택(ex: K-Means, PCA 등)
성능 평가
- 분류: Accuracy, Precision, Recall, F1-score, ROC-AUC 등
- 회귀: MAE, RMSE, R2, MAPE 등
- 비지도(군집): 실루엣 계수 등
1-2 머신러닝을 하기 전 데이터 전처리 과정
1. 데이터 전처리
데이터 전처리: raw 데이터에서 불필요하거나 노이즈가 있는 부분을 처리하고 분석 목적에 맞는 형태로 만드는 과정
필요성
- 모델 정확도 및 신뢰도 향상
- 이상치나 결측치가 많은 상태로 학습하면 예측 성능이 크게 떨어짐
- 효율적인 데이터 분석과 모델 훈련을 위해 필수적인 단계
2. 결측치 처리
결측치 발생 원인
- 센서 고장, 측정 오류, 환경적 문제 등
- 사람이 수기로 입력하는 경우 누락
결측치 처리 기법
- 삭제
- 간단하지만 데이터 손실 발생
- 결측치가 전체 데이터에서 매우 소수일 때 적합
- 대체
- 평균값(Mean) & 중앙값(Median)으로 대체 -> 수치형 데이터에서 많이 사용, 데이터 분포 왜곡이 비교적 적음
- 평균값(Mean): 데이터가 정규분포에 가까울 때
- 중앙값(Median): 데이터가 한쪽으로 치우치거나, 이상치가 있을 때
- describe()를 확인하였을 때, Mean과 50% 값의 차이가 거의 없으면 Mean, 차이가 크면 Median 대
- 최빈값(Mode)로 대체 -> 범주형 데이터에서 사용
- 예측 모델로 대체 -> 회귀/분류 모델을 이용해 결측값 예측
- 평균값(Mean) & 중앙값(Median)으로 대체 -> 수치형 데이터에서 많이 사용, 데이터 분포 왜곡이 비교적 적음
import pandas as pd
import numpy as np
df = pd.DataFrame(data)
1) 결측치 제거
df_drop = df.dropna()
2) 평균값(mean) 대체
df_mean = df.copy()
df_mean = df_mean.fillna(df_mean.mean(numeric_only=True))
3) 중앙값(median) 대체
df_median = df.copy()
df_median = df_median.fillna(df_median.median(numeric_only=True))
4) 최빈값(mode) 대체
df_mode = df.copy()
mode_values = df_mode.mode().iloc[0]
df_mode = df_mode.fillna(mode_values)
3. 이상치 탐지 및 제거
이상치
- 정상 범주에서 크게 벗어나는 값
- 장비 오작동, 환경적 특이 상황 등 원인이 다양함
탐지 기법
- 통계적 기법 (3σ Rule)
- 데이터가 정규분포를 따른다고 가정하고, 평균에서 ±3σ(표준편차) 범위를 벗어나는 값을 이상치로 간주
- 직관적이고 간단하나, 정규성 가정이 틀릴 수 있음.
- 박스플롯(Boxplot) 기준
- 사분위수(IQR = Q3 - Q1)를 이용해 ‘Q1 - 1.5×IQR’, ‘Q3 + 1.5×IQR’를 벗어나는 데이터를 이상치로 간주
- 분포 특성에 영향을 적게 받는 장점

- 머신러닝 기반
- 이상치 탐지 알고리즘(Isolation Forest, DBSCAN 등)
- 복합적 패턴을 고려할 수 있음
처리 기법
- 이상치 단순 제거
- 이상치 값 조정(클리핑, Winsorizing 등)
- 별도로 구분하여 모델에서 제외하거나 다른 모델(이상치 예측 모델)로 활용
4. 정규화/표준화(Scaling)
왜 필요한가?
- 모델(거리 기반 알고리즘, 딥러닝 등)에 따라 특정 변수의 스케일이 크게 영향을 미칠 수 있음.
정규화(MinMaxScaler)
- 모든 값을 0과 1 사이로 매핑

- 특징
- 값의 스케일이 달라도 공통 범위(0~1)로 맞출 수 있음.
- 딥러닝에서 주로 사용
- 딥러닝(신경망), 이미지 처리 등에서 입력값을 0~1로 제한해야 하거나, 각 특성이 동일한 범위 내 있어야 하는 경우
- 거리 기반 알고리즘(유클라디안 거리 사용)이나 각 특성의 범위를 동일하게 맞춤으로써 계산 안정성을 높이고 싶을 때
- 최소값·최대값이 극단값(Outlier)에 민감. 만약 극단치가 있으면 대부분의 데이터가 [0, 1] 구간 내부 한쪽에 치우침.
- 새로운 데이터가 기존 최대값보다 커지거나 최소값보다 작아지는 경우. 스케일링 범위를 벗어날 수 있어 재학습하거나 다른 처리 필요
표준화(StandardScaler)
- 평균을 0, 표준편차를 1로 만듦
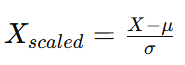
- 특징
- 분포가 정규분포에 가깝게 변형
- 다양한 선형 모델(회귀, 로지스틱 회귀에서 주로 사용)
- 평균이 0, 표준편차로 1로 맞춰지므로, 정규분포 가정을 사용하는 알고리즘(선형회귀, 로지스틱회귀, SVM 등)에 자주 쓰임.
- 변환된 값들이 이론적으로 -∞ ~ +∞ 범위를 가질 수 있음
- 데이터가 특정 구간([0, 1] 등)에 고정되지 않음.
- 데이터 분포가 심하게 치우쳐 있으면 평균과 표준편차만으로는 충분한 스케일링이 되지 않을 수 있음(로그 변환, RobustScaler 등 추가 고려)
from sklearn.preprocessing import MinMaxScaler, StandardScaler
scaler = MinMaxScaler() or StandardScaler()
# train, test 없을 때
df_scaled = scaler.fit_transfrom(df)
# train, test 있을 때
scaler.fit(X_train)
X_train_scaled = scaler.transfrom(X_test)
5. 불균형 데이터 처리
불균형 데이터: 정상 99%, 불량 1%처럼 한 클래스가 극도로 적은 경우
문제점: 모델이 극도로 적은 클래스를 거의 예측하지 못할 가능성이 큼(편향 발생)
해결 기법
- Oversampling
- Random Oversampling
- 소수 클래스의 데이터를 단순 복제하여 개수를 늘림
- SMOTE(Synthetic Minority Over-sampling Technique)
- 소수 클래스를 무작정 복사하는 것이 아닌 비슷한 데이터들을 서로 섞어서 새로운 데이터 생성
- Random Oversampling
- Undersampling
- 다수 클래스 데이터를 줄이는 방식
- 데이터 손실 위험이 있지만 전체 데이터 균형을 맞출 수 있음.
- 혼합 기법
- SMOTE와 언더샘플링을 적절히 섞어서 사용
from imblearn.over_sampling import SMOTE
X = df.drop('타겟 컬럼', axis=1)
y = df['타겟 컬럼']
smote = SMOTE(random_state=42)
X_res, y_res = smote.fit_resamplt(X, y)
6. 범주형 데이터 변환
One-Hot Encoding
- 범주형 변수를 각각의 범주별로 새로운 열로 표현, 해당 범주에 해당하면 1, 아니면 0
- 장점: 범주 간 서열 관계가 없을 때 사용
- 단점: 범주가 매우 많으면 차원이 커짐
Label Endocing
- 범주를 숫자로 직접 매핑
- 단순하지만 모델이 숫자의 크기를 서열 정보로 잘못 해석할 수 있음
# 범주형 변수 변환 (One-Hot Encoding)
import pandas as pd
df = pd.get_dummies(df, columns=['범주형 변수'])
# 범주형 변수 변환 (Label Encoding)
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
df['범주형 변수'] = encoder.fit_transform(df['범주형 변수'])
7. Feature Engineering
Feature Engineering: 모델 성능 향상을 위해 기존 데이터를 변형, 조합하여 새로운 Feature를 만드는 작업
중요성
- 복잡한 데이터 구조 안에 존재하는 패턴을 효과적으로 추출해 모델이 쉽게 학습하게 함.
파생 변수 생성
- 날짜 파생 변수
- 년(year), 월(month), 일(day), 요일(dayofweek), 시간(hour, minute, second) 등
- 수치형 변수 조합
- ex) '온도'와 '습도' 컬럼이 있을 때, 새로운 Feature인 '온도x습도'를 생성
- 로그 변환, 제곱근 변환 등
- 분포가 매우 치우친 변수(오른쪽 꼬리가 긴 경우)에 로그 변환을 적용하여 정규성에 가까워지도록 조정
# 날짜 파생 변수
df['year'] = df['timestamp'].dt.year
df['month'] = df['timestamp'].dt.month
df['day'] = df['timestamp'].dt.day
df['hour'] = df['timestamp'].dt.hour
df['minute'] = df['timestamp'].dt.minute
df['day_of_week'] = df['timestamp'].dt.dayofweek (월: 0, 화: 1, 수: 2, 목: 3, 금: 4, 토: 5, 일: 6)
df['is_weekend'] = df['day_of_week'].apply(lambda x: 1 if x >= 5 else 0) (주말 여부 확인)
# 수치형 변수 조합
df['조합 변수'] = df['변수1'] * df['변수2']
변수 선택
- 상관관계
- 두 변수 간 상관계수가 높은 상황인 경우 다중공선성 의심. 하나만 남기거나 둘 다 제거 고려
- VIF
- 회귀분석에서 다중공선성 문제를 파악할 때 사용
- VIF는 어떤 변수 하나가 다른 변수들과 얼마나 겹치는지 수치로 보여주는 지표
- 모델 기반 중요도(Feature Importance)
- 트리 기반 모델(Random Forest, XGBoost 등)을 훈련 후 중요도가 낮은 변수 제거
변수 간 상호작용 추가
- 다항식/교차 항 생성
- 제조 공정에서 온도, 압력, 속도 등이 곱해져야 비로소 의미가 생기는 경우가 많음
✏️ 오늘의 질문
1. Open API란 무엇인가?
누구나 사용할 수 있도록 공개된 프로그래밍 인터페이스
2. 멀티모달이란 무엇인가?
AI가 텍스트, 이미지, 음성, 영상, 센서 데이터 등 서로 다른 형태의 정보(Modality)를 결합하여 이해하거나 생성하는 기술
📌추가로 해야 할 점
머신러닝 기초, 스탠다드
'품질관리(QAQC) 데이터 부트캠프(본캠프)' 카테고리의 다른 글
| 본캠프_15주차(월)_TIL(분류, 베이직) (0) | 2025.12.22 |
|---|---|
| 본캠프_14주차(금)_TIL(회귀, 스탠다드) (0) | 2025.12.19 |
| 본캠프_14주차(수)_TIL(실전 프로젝트) (0) | 2025.12.17 |
| 본캠프_14주차(화)_TIL(실전 프로젝트) (0) | 2025.12.16 |
| 본캠프_14주차(월)_TIL(실전 프로젝트) (0) | 2025.12.15 |