✅ 오늘 한 것
베이직, 실무에 쓰는 머신러닝 기초
✏️ 오늘 배운 점
실무에 쓰는 머신러닝 기초
1. 분류 모델
지도학습이란?
- 입력 데이터(특징, Feature)와 정답(Label)이 주어졌을 때 모델이 정답을 예측하도록 학습하는 방식
분류(Classification)
- 분류의 목적
- 데이터가 어느 범주(클래스)에 속하는지 예측.
- 분류 문제를 해결하기 위해 자주 활용되는 알고리즘: Logistic Regression, SVM
로지스틱 회귀(Logistic Regression)
- 선형 회귀처럼 입력값의 선형 결합을 취하지만 결과를 0~1 사이의 확률로 변환하기 위해 로지스틱 함수(시그모이드 함수)를 사용.

- 장점
- 계산이 빠르고 구현이 간단함.
- 결과 해석이 용이
- 단점
- 복잡한 비선형 패턴을 학습하기엔 한계가 있음.
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import accuracy_score, classification_report
X = df.data
y = df.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
logistic_model = LogisticRegression(max_iter=200)
logistic_model.fit(X_train, y_train)
y_pred = logistic_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
classification = classification_report(y_test, y_pred, target_names = df.target_names)
SVM(Support Verctor Machine)
- 데이터를 가장 잘 구분하는 경계를 찾는 알고리즘

- 장점
- 차원이 높은 데이터에서도 좋은 성능을 보일 수 있음.
- 결정 경계를 명확하게 찾는 경우 예측 성능이 우수함.
- 결정 경계란? -> SVM이 찾은 최적의 분류선
- 단점
- 파라미터(C, 커널 종류 등)를 적절히 찾아야 하므로 튜닝 비용이 큼.
- 대규모 데이터 세트에 대해서는 학습 속도가 느릴 수 있음.
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, classification_report
X = df.data
y = df.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
svm_model = SVC()
svm_model.fit(X_train, y_train)
y_pred = svm_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
classification = classification_report(y_test, y_pred, target_names = df.target_names)
K-NN(K-최근접 이웃)
- 간단하지만 대규모 데이터에서 계산량이 큼.

나이브 베이즈(Naive Bayes)
- 통계적 가정(독립성)에 기반하므로 계산이 빠름.
- 스팸 필터 등에서 자주 사용

신경망(MLP) 또는 딥러닝 모델
- 복잡도는 높지만 대규모 데이터에서 강점

모델 평가 방법
Cross Entropy, Hinge Loss
- 분류 모델에 사용되는 손실함수
- Binary Cross Entropy / Cross Entropy
- Binary Cross Entropy 2진 분류에서 자주 사용
- 일반적으로 다중 분류에서 Cross Entropy를 사용
- 예측 확률이 실제 레이블과 얼마나 차이가 있는지 측정
- Hinge Loss
- SVM(Support Vector Machine)에서 많이 사용
- 마진을 고려하여 오분류된 샘플에 페널티를 부여
- Binary Cross Entropy / Cross Entropy
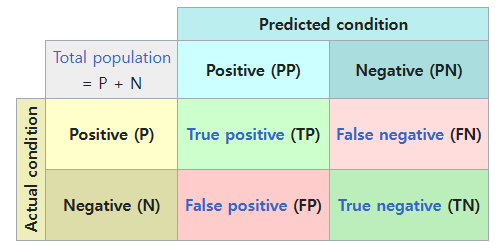
혼동 행렬(Confusion Matrix)
- 실제 클래스와 예측 클래스의 관계를 행렬 형태로 나타낸 것.
- True Positive(TP), False Positive(FP), False Negative(FN), True Negative(TN)
- 분류 모델 해석의 기초이므로, 용어와 의미를 잘 숙지해야 함.
- Precision(정밀도)
- 예측을 Positive라고 한 사례 중 실제로 Positive인 비율
- TP/(TP+FP)
- Recall(재현율)
- 실제 Positive 사례 중 모델이 positive로 맞춘 비율
- TP/(TP+FN)
- F1-score: Precision과 Recall의 조화평균
- 두 지표가 모두 중요한 경우를 종합적으로 평가
- (2*Precision*Recall)/(Precision+Recall)
ROC 곡선과 AUC(Area Under the Curve)
ROC 곡선
- 임계값(Threshold)를 변화시키며, TPR(True Positive Rate)과 FPR(False Positive Rate)의 변화를 시각화한 곡선
- TPR(True Positive Rate)
- 재현율(Recall) or 민감도(Sensitivity)
- 실제 양성(Positive) 샘플 중 모델이 양성이라고 예측한 비율
- 0~1 사이의 값을 가지며 1에 가까울수록 좋음

- FPR(False Positive Rate)
- 실제 음성(Negative) 샘플 중 모델이 양성이라고 잘못 예측한 비율
- 0~1 사이의 값을 가지며 0에 가까울수록 좋음

- TPR(True Positive Rate)
- TPR과 FRP은 트레이드 오프 관계 (한 쪽이 좋다면 한 쪽은 좋지 않음)
AUC
- ROC 곡선 아래 면적.
- 1에 가까울수록 모델이 우수함.

import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve, roc_auc_score
X = df.data
y = df.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
model = LogisticRegression(max_iter=500)
model.fit(X_train, y_train)
y_proba = model.predict_proba(X_test)[:, 1]
fpr, tpr, thresholds = roc_curve(y_test, y_proba)
auc_score = roc_auc_score(y_test, y_proba)베이직
품질관리 개론 & SPC 기초
품질관리(QA vs QC)
- QA(Quality Assurance, 품질보증): 제품 또는 서비스가 요구된 품질을 충족하도록 사전 예방적인 활동 수행
- 프로세스 중심, 품질 정책 및 절차 수립, 지속적인 개선
- QC(Quality Control, 품질관리): 생산된 제품이 요구된 품질 기준을 충족하는지 검사하고 결함을 식별하는 활동
- 제품 중심, 샘플 검사, 결함 제거
Six Sigma란?
- 데이터 기반의 품질 관리 및 프로세스 개선 방법론
- 100만 개 제품 중 3.4개 이하의 결함을 목표
- 공정 데이터가 정규분포를 따른다고 가정
- 정규분포를 따르지 않는 경우 Box-Cox 변환, Johnson 변환 등의 방법을 사용해 데이터를 정규화하여 6시그마 기법 적용
- 비정규분포일 경우 공정 능력 지표(예: Cpk, Ppk)를 사용할 수 있으며, 비모수적 기법을 활용하여 데이터 분석
SPC(Statistical Process Control)란?
- 통계적 기법을 활용하여 공정 변동을 모니터링하고 제어하는 품질 관리 방법론
- 품질 관리 차트(Control Chart)를 사용하여 공정이 정상 범위 내에서 운영되는지 확인
- 이상 변동(Assignabel Causes)과 자연 변동(Common Causes)을 구별하여 개선 활동 수행
DMAIC 방법론
- Define (정의): 문제 정의 및 프로젝트 목표 설정
- 고객의 요구 사항 및 핵심 성과 지표(KPI) 설정
- 고객의 기대를 파악하고 제품 또는 서비스의 필수 품질 요소 정의
- KPI(Key Performance Indicator, 핵심 성과 지표)
- 프로젝트의 성과를 측정하는 기준이 되는 정량적 목표
- 기업 또는 조직이 설정한 목표 달성 여부를 평가하기 위해 사용
- 특징:
- 측정 가능하고 구체적인 데이터 기반 지표
- 일정 기간 내에 달성해야 할 목표를 명확히 설정
- 조직의 전략적 목표와 일치해야 함.
- CTQ(Critical to Quality) 요소 식별
- 고객의 요구 사항 중에서 제품/서비스의 품질을 결정하는 핵심 요소
- CTQ 요소 식별 단계
- 고객의 기대 사항(Customer Requirements) 파악
- 고객이 제품이나 서비스에서 기대하는 핵심 품질 속성 정의
- 고객 요구 사항을 품질 특성으로 변환
- 고객의 주관적인 요구를 정량적이고 측정 가능한 품질 특성으로 변환
- CTQ 트리(CTQ Tree) 활용
- 고객 요구 사항을 세부적인 품질 속성으로 계층 구조화하여 CTQ 요소 도출
- CTQ 요소의 우선순위 결정
- CTQ 요소들 중에서 가장 중요한 요소를 선정하여 개선 활동의 목표 설정
- 고객 불만 및 품질 데이터 분석을 통해 결정 가능
- 고객의 기대 사항(Customer Requirements) 파악
- 고객의 요구 사항 및 핵심 성과 지표(KPI) 설정
- Measure (측정): 현재 공정 성능 및 결함율 측정
- 데이터를 수집하고 공정 변동 분석
- DPMO(백만 개당 결함 수) 계산
- 결함 수(Defects) 측정: 특정 샘플에서 발견된 총 결함 개수 측정
- 기회 수(Opportunities) 측정: 한 개 제품에서 발생할 수 있는 결함의 총 개수 측정
- 샘플 크기(Units) 결정: 검사한 총 제품 개수 측정
- DPMO 계산 공식
DMPO = (총결함수 / 총검사단위 * 단위당기회수) * 1000000
- Analyze (분석): 원인 분석 및 문제의 핵심 요소 파악
- 원인-결과 분석(Fishbone Diagram, 5 Why 기법 활용)
- Fishbone Diagram
- 문제(결함 또는 프로세스 개선 필요 사항)의 근본 원인을 파악하기 위해 사용되는 시각적 도구
- 5 Why 기법
- 특정 문제의 근본 원인을 찾기 위해 "왜?"라는 질문을 5번 반복하여 원인을 심층적으로 분석
- Fishbone Diagram
- 프로세스 통계 분석(ANOVA, 회귀 분석 등 활용)
- ANOVA (Analysis of Variance, 분산 분석)
- 여러 그룹 간의 평균 차이가 통계적으로 유의미한지를 분석하는 방법
- 공정 개선 후 A, B, C 공장에서 생산된 제품의 불량률이 통계적으로 차이가 있는지 분석 가능
- 회귀 분석 (Regression Analysis)
- 변수들 간의 관계를 분석하여 특정 변수가 결과에 미치는 영향을 정량적으로 평가하는 기법
- 선형 회귀(Linear Regression), 다항 회귀(Multiple Regression) 등
- ANOVA (Analysis of Variance, 분산 분석)
- 원인-결과 분석(Fishbone Diagram, 5 Why 기법 활용)
- Imporve (개선): 프로세스 개선 및 최적화 실행
- DOE(Design of Experiment) 실험 설계를 통한 최적화
- 여러 변수들이 결과에 미치는 영향을 체계적으로 분석하여 최적의 조건을 찾는 방법론
- 실험 설계를 활용하면 공정을 변경하기 전에 다양한 변수 조합을 검토하여 최상의 성능 도출 가능
- 주요 기법:
- 완전 요인 실험(Full Factorial Design): 모든 요인 조합을 실험하여 최적 조합을 찾음
- 부분 요인 실험(Fractional Factorial Design): 중요한 변수만 실험하여 실험 비용과 시간 절감
- 반응 표면 방법(Response Surface Methodology, RSM): 최적의 조합을 찾기 위한 고급 기법
- Lean 기법(낭비 제거, 속도 개선) 적용
- 불필요한 낭비를 제거하고 공정을 효율적으로 운영하기 위한 품질 개선 전략
- 7가지 낭비 요소(7 Wastes, Muda) 제거
- 과잉 생산(Overproduction): 실제 필요 이상으로 생산하는 낭비
- 대기 시간(Waiting): 공정 대기 시간으로 인해 발생하는 비효율
- 불필요한 운반(Transportation): 과도한 자재 이동으로 인한 낭비
- 과도한 처리(Over-processing): 필요 이상으로 복잡한 공정을 적용하는 문제
- 재고(Inventory): 과도한 원자재 및 제품 재고 보유로 인한 비용 증가
- 불량(Defects): 품질 문제로 인해 추가적인 재작업이 필요한 경우
- 불필요한 동작(Motion): 작업자가 불필요한 움직임을 해야 하는 경우
- Lean 도구 및 기법
- 5S (정리, 정돈, 청소, 청결, 습관화): 작업 환경을 정리하여 생산성을 높이는 방법
- 칸반(Kanban) 시스템: 시각적 관리 도구를 활용하여 생산 흐름 최적화
- 가치 흐름 분석(Value Stream Mapping, VSM): 프로세스 단계별 낭비를 분석하여 개선 기회 도출
- DOE(Design of Experiment) 실험 설계를 통한 최적화
- Control (관리): 개선된 공정을 유지하고 지속적인 관리 수행
- SPC 활용하여 품질 변동 모니터링
- 표준 작업 절차(SOP) 문서화 및 교육
공정 변동의 유형
- 자연 변동(Common Cause Variation)
- 공정에서 본질적으로 발생하는 변동으로, 모든 공정에서 불가피하게 나타남
- 공정이 안정적이고 정상적으로 운영되는 경우에도 발생하는 변동이며, 장기적인 개선을 통해 최소화할 수 있음
- 원인:
- 작업자의 피로로 인한 생산 속도 변화
- 환경적 요인 (온도, 습도 등)
- 특징:
- 예측 가능하고 일정한 범위 내에서 변동
- SPC 차트에서 중심선을 기준으로 랜덤하게 분포하는 패턴을 보임
- 제거할 수 없지만 지속적인 개선을 통해 최소화 가능
- 해결 방법:
- 지속적인 유지보수 및 예방적 관리
- 공정 최적화 및 작업 표준화
- 장기적인 개선 활동 적용
- 특별 변동(Assignabel Cause Variation)
- 공정 내에서 특정 원인으로 인해 발생하는 비정상적인 변동
- 갑작스럽게 발생하며, 원인을 찾고 해결하지 않으면 품질 문제를 유발할 수 있음
- 원인:
- 작업자의 실수 또는 부적절한 조작
- 원자재 품질 문제 (불량 원자재, 오염된 재료 등)
- 급격한 환경 변화 (예: 갑작스러운 온도 변화, 습도 문제 등)
- 특징:
- 예측 불가능하며 갑작스럽게 나타남
- SPC 차트에서 관리 한계를 벗어나는 패턴을 보임
- 원인을 신속히 찾아 해결해야 함
- 해결 방법:
- 공정 내 주요 변수 모니터링 및 실시간 감지 시스템 도입
- 문제 발생 시 근본 원인 분석 (5 Why 기법, Fishbone Diagram 활용)
- 작업자 교육 및 품질 관리 절차 강화
✏️ 오늘의 질문
1. 왜 정확도(Accuracy)만으로 분류 모델의 성능을 판단하면 안 되나요?
데이터가 불균형(예: 정상 99%, 불량 1%)한 경우에 대부분을 정상이라 예측해도 정확도가 매우 높아져 버린다. 그래서 Precision, Recall, F1-score, ROC-AUC 같은 지표를 함께 고려해야 모델의 진짜 성능을 평가할 수 있다.
2. 불량이 1% 미만인 극단적으로 불균형한 제조 공정 데이터도 모델링이 가능한가?
가능하지만 불균형 문제가 심각할 것이다. 따라서, 오버샘플링(SMOTE), 언더샘플링 등 데이터를 재구성하거나 클래스 가중치(Weight) 조정 같은 기법을 사용해야 한다. 평가 시에도 Recall, Precision, ROC-AUC, PR 곡선 등을 종합적으로 확인한다.
📌추가로 해야 할 점
실무에 쓰는 머신러닝 기초, 스탠다드, 베이직
'품질관리(QAQC) 데이터 부트캠프(본캠프)' 카테고리의 다른 글
| 본캠프_15주차(수)_TIL(클러스터링, 차원 축소, 이상 탐지, AI 서비스 개발) (0) | 2025.12.24 |
|---|---|
| 본캠프_15주차(화)_TIL(앙상블 기법, 베이직, 스탠다드) (0) | 2025.12.23 |
| 본캠프_14주차(금)_TIL(회귀, 스탠다드) (0) | 2025.12.19 |
| 본캠프_14주차(목)_TIL(머신러닝 기초) (0) | 2025.12.18 |
| 본캠프_14주차(수)_TIL(실전 프로젝트) (0) | 2025.12.17 |